
What Is Event Correlation? A Practical Guide for Teams Connecting Alerts, Workflows, and Root Cause Analysis
Learn what event correlation is, how teams connect alerts and workflows, and why better correlation speeds triage and root cause analysis.
What Is Event Correlation? A Practical Guide for Teams Connecting Alerts, Workflows, and Root Cause Analysis
What is event correlation, really? Is it just the act of grouping similar alerts so dashboards look cleaner, or is it the operating logic that helps teams tell the difference between one real incident and twenty noisy symptoms? If your teams keep getting flooded by alerts from infrastructure, applications, integrations, and customer-facing systems, but still struggle to understand what actually broke first, what exactly is missing? More monitoring? More dashboards? Or a better way to connect the signals into one trustworthy story?
That is why event correlation matters more than it may seem at first glance. Event correlation is the process of identifying relationships between alerts or events across systems so teams can reduce noise, spot incident patterns faster, and investigate root causes with more context. In simpler terms, it is how the business stops treating every alert as an isolated problem and starts asking which alerts belong to the same operational event.
The real issue is that many teams still treat alert streams like separate inboxes. Infrastructure monitoring sends one set of notifications. Application monitoring sends another. Support sees customer complaints. Workflow tools show retries or failures somewhere else. If nobody correlates those signals, what happens? Teams chase symptoms in parallel, open duplicate incidents, and lose time deciding whether three warnings are one issue or three different ones.
Splunk's guide to event grouping and correlation is useful because it explains correlation as finding relationships between events across multiple sources based on time, transaction patterns, and shared characteristics. Helpful? Absolutely. But is "group related events" enough by itself? Not really. Correlation becomes truly useful only when the grouped signal drives a better workflow: clearer triage, fewer duplicate pages, sharper escalation, and faster root-cause analysis.
So what should a stronger team ask? Not just "Can we reduce alert noise?" Ask instead: which signals belong together, what fields actually matter for grouping, what event should open a real incident, what exceptions deserve human review, and which correlated pattern should trigger the next operational action? Those are event-correlation questions too, and they sound much closer to workflow design than basic monitoring configuration. That is exactly the point.
That is also the category shift hiding underneath the term. The market does not need one more alert view alone. It needs execution infrastructure that can interpret grouped signals, preserve operator trust, and move the business from noisy telemetry to an owned response path. The future of event correlation will not be won by the tool that compresses the most alerts. It will be won by the system that makes incident truth, ownership, and next action visible fast enough for teams to act with confidence.
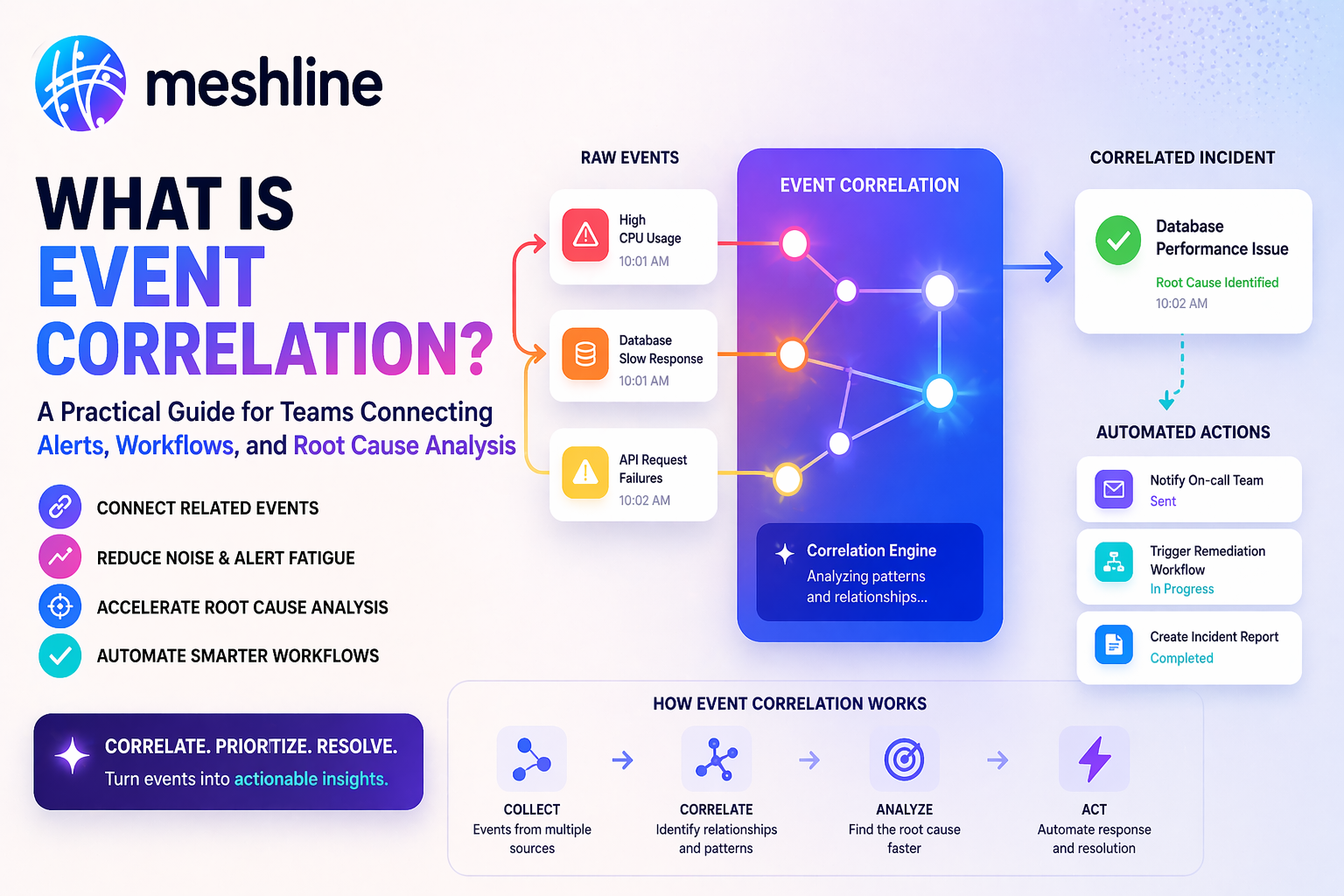
What event correlation means in practice
Event correlation is the practice of combining related alerts or events into one operational picture. In a working system, the team does not treat every CPU spike, queue lag, failed webhook, and support complaint as separate until proven otherwise. It asks whether those signals are connected by time, service, topology, dependency path, or business outcome.
Would a simple example help? Imagine an ecommerce platform sees rising API latency, webhook retries from a fulfillment system, and support tickets about delayed order confirmations. If those events stay siloed, one team investigates the app, another checks integrations, and support treats the complaints as isolated. But if the signals are correlated properly, the business can quickly see that one degraded service is creating downstream symptoms across multiple tools. That is the difference between watching noise and recognizing a real event pattern.
That is why correlation is not only about cleaner dashboards. It is about deciding whether multiple alerts represent one incident, one transaction failure, one degraded dependency, or several independent issues. If the team cannot answer that clearly, root-cause analysis gets slower because the first hour of incident response is spent arguing about scope instead of responding.
Why event correlation matters when alert volume rises
Have you ever seen a team with "lots of observability" still struggle to triage incidents quickly? That usually means the monitoring is stronger than the correlation logic. As systems get more distributed, one failure can create many different alerts. A database issue can slow APIs, which can break background jobs, which can delay customer notifications, which can trigger support tickets, which can generate business alarms about order completion. Are those separate events? Sometimes. But often they are one unfolding operational issue viewed through several tools.
Splunk's Event iQ overview is helpful because it frames event correlation as a noise-reduction and context problem, not just a search problem. That framing matters. If an alerting system groups everything too loosely, teams miss meaningful differences. If it groups nothing, they drown in duplication. So what actually matters? The grouping logic has to reflect how the business experiences incidents, not just how individual tools label them.
This is where many teams get stuck. They know alert fatigue is real, but they still build correlation rules around the easiest shared fields instead of the most meaningful relationships. What happens then? Correlated episodes may look tidy while still mixing unrelated events or splitting one real incident across several groups. The business feels faster on paper and slower in practice.
The hidden cost of weak event correlation is bigger than most teams admit:
- duplicate incidents get opened for the same operational failure
- on-call teams spend time triaging noise instead of root cause
- support and ops tell different stories about the same issue
- workflow automations trigger repeatedly from overlapping symptoms
- leadership sees many alerts but little clarity about the real incident
That is why event correlation should be treated as an execution-layer problem, not just a monitoring setting.
The core parts of useful event correlation
So what actually makes event correlation useful? A stronger correlation workflow usually has five parts:
1. A meaningful event model
Not every signal deserves the same weight. The team needs a clear sense of which events are symptoms, which are triggers, and which are true operational milestones.
2. Grouping logic that matches reality
Correlation should use fields that reflect real relationships: service, environment, dependency, affected entity, time proximity, event type, or transaction context. If the rules are too broad or too narrow, the grouped output becomes hard to trust.
3. Clear separation between correlated noise and actionable incidents
Correlation should help the team decide when a pattern is worth escalating. If every correlated group still becomes a human-page event, what did the workflow really improve?
4. A handoff path into triage and response
This is where many systems stop too early. Correlating alerts is only helpful if the output reaches the right queue, owner, or incident workflow.
5. Feedback from investigation outcomes
Teams should refine correlation logic based on what actually happened in incidents. Which fields grouped noise correctly? Which signals were misleading? Which correlated episodes should have merged or split differently next time?
A named-system event correlation example
Would a concrete workflow make this easier to pressure-test? Imagine an operations team uses Datadog for infrastructure and application monitoring, Splunk for log search and event grouping, Slack for incident routing, and a workflow tool to coordinate remediation tasks. A spike in checkout latency appears in Datadog. Around the same time, Splunk sees repeated payment-service timeout events. Support also starts hearing about failed checkouts. What should happen next?
First, the system should not open three separate stories. Correlation logic should test whether the alerts share the same service, time window, and impacted transaction path. If they do, the workflow should create one correlated incident or episode with enough context for triage. Slack should receive one routed summary rather than several fragmented alerts. The operations workflow should then track the correlated issue through investigation and response rather than spawning parallel work on the same symptom set.
Datadog's event correlation documentation is useful because it frames correlation around cases, patterns, and triage rather than just individual events. But correlation features alone do not solve the whole problem. If the business still lacks a clear rule for when a correlated group becomes a real incident, or which owner should respond first, the team still spends precious minutes negotiating the next move.
Why event correlation is essential for root cause analysis
Root cause analysis slows down when the team cannot see the relationship between symptoms. If one service alarm triggers four downstream retries, three support complaints, and a queue delay, which signal matters most? Which one happened first? Which one merely confirms the damage? Event correlation helps the team answer those questions earlier by stitching together evidence across tools instead of leaving each signal isolated.
New Relic's correlation decision documentation is helpful because it shows how teams can define and refine the conditions that decide whether alerts belong together. That matters because root-cause analysis is rarely only about finding one bad line in one service. It is about reconstructing the sequence: which event started the issue, which dependencies amplified it, and which symptoms were just downstream effects.
If the team still begins every incident by copying timestamps between tabs, what does that suggest? Usually not a lack of data. It suggests the signals are not being organized into one trustworthy path quickly enough.
What teams usually get wrong in rollout week
Want a fast way to tell whether an event-correlation rollout is actually ready? Look at the first week after launch. That is where the gaps usually appear. The tool groups alerts, but the team still cannot tell whether the grouped set is actionable. Or the workflow suppresses too aggressively and hides useful nuance. Or the correlation output is visible in one tool but never reaches the actual responders.
These rollout-week mistakes are common:
- grouping events by convenience fields instead of operationally meaningful ones
- merging unrelated alerts because they happen near each other in time
- suppressing signals without preserving enough investigation context
- failing to define when a correlated group should escalate into a real incident
- skipping review of false merges and missed merges after actual incidents
A practical rollout test is simple. Pull the first ten correlated groups. Can the team explain why those alerts were grouped, which one represented the likely trigger, what downstream effects were included, and whether the resulting incident path helped response? If not, is the correlation logic really working, or is it just compressing noise?
Event correlation examples that improve triage
Example one: a webhook service fails repeatedly because an upstream authentication token expires. The monitoring stack emits retries, queue growth, latency spikes, and a support note about delayed notifications. A strong event-correlation workflow groups those into one issue tied to the webhook service rather than four separate incidents. What changed? Not the failure. The triage path got clearer.
Example two: a noisy but non-critical service emits many transient warnings during a deploy. If the system correlates those warnings with a broader platform incident incorrectly, the team may overreact and page the wrong owners. That is why grouping logic has to respect service boundaries and severity context, not just timestamp overlap.
Example three: a payment provider outage creates error spikes across checkout, subscription renewal, and internal billing reconciliation. Without correlation, each team may think its own workflow is failing independently. With stronger correlation, the business can see one dependency issue expressing itself through multiple workflows and coordinate one response instead of three partial ones.
How to make event correlation actually operational
Would the best event-correlation system be the one that merges the most alerts? Usually no. The better system is the one that turns signal relationships into a faster, more trustworthy operating response with less manual interpretation.
Here is the stronger pattern:
- define which events are triggers versus symptoms
- correlate using business-meaningful fields and dependency context
- route correlated groups into one visible triage path
- preserve enough context so investigators can still see the full sequence
- review correlation quality after incidents to improve future grouping
That is why the business question matters so much: what exactly is this event-correlation workflow supposed to produce? Fewer duplicate incidents? Faster root-cause analysis? Less on-call fatigue? Better workflow routing? Stronger remediation timing? If the answer stays vague, the correlation logic usually becomes shallow because the team is not aligning it to a concrete operational outcome.
Where Meshline fits
So where does Meshline belong in a topic that sounds like observability tooling territory? Right where event correlation stops being a single-tool feature and starts becoming a coordination workflow.
Most teams do not only have an alert problem. They have an execution problem around alerts. Datadog knows one signal. Splunk knows another. Support sees customer effects. Slack sees who got paged. Workflow systems know which remediation tasks were opened. But who can see the full trigger-to-outcome path in one governed flow? Who can tell which correlated signal deserves escalation, which owner should act next, and which downstream workflow is actually affected without stitching the answer together manually?
That is Meshline's angle. Meshline is not trying to replace your monitoring stack. It is the execution layer that keeps correlated event movement visible across the systems already handling alerts, routing, triage, and remediation. Instead of forcing operators to reconstruct the incident story after the fact, Meshline can keep the correlation path inspectable while it is running: what events were grouped, what logic grouped them, which owner received the issue, what workflow paused, and what outcome the business should trust next.
That is also why this topic overlaps with Workflow Orchestrator, Support Triage Copilot, and the Automation glossary. Event correlation is not just a monitoring detail. It is an operating path for incident understanding. If grouped signals, workflow ownership, and response actions are scattered, the workflow is still asking humans to provide infrastructure manually.
Event correlation checklist for teams
Use this checklist before calling the system healthy:
- Does the team know which signals are symptoms and which are likely triggers?
- Are correlation rules based on operationally meaningful fields?
- Can responders see why events were grouped together?
- Does one correlated issue route into one clear triage path?
- Are false merges and missed merges reviewed after incidents?
- Can the team trace correlated groups into root-cause analysis without reopening the same story manually?
- Are support and operations seeing the same incident narrative?
- Is the business measuring triage speed and duplicate-incident reduction, not just alert compression?
Final takeaway
Event correlation is not just the act of grouping alerts. It is the operating sequence that turns noisy signals into a clearer incident story, faster triage, and better root-cause analysis. If your team still spends too much time deciding whether alerts belong together, the problem is probably not effort. It is correlation design, ownership, and control.
That is the category shift Meshline cares about. The future does not belong to teams with the most alerts. It belongs to self-operating business systems with better trigger-to-outcome execution, cleaner incident routing, and stronger visibility across the tools that decide whether a signal is truly actionable. If your event-correlation workflow still depends on people stitching together the truth after the fact, the next step is not another alert rule in isolation. The next step is to map the exact grouping logic, owner, escalation path, and workflow action that define incident trust, then redesign the response flow before the next alert storm becomes another root-cause guessing session.